Say you have a photograph which (probably) contains a PDF417 barcode, and you’d like to know what’s in it. ZXing sounds like the tool for the job, but back in 2018, it failed on all my test images. What’s a fellow to do? Over the next three years, I intermittently worked on Ruby417, a library to reliably locate and decode PDF417 barcodes.
{kind=link}
I never got around to the decoding part, but I learned some interesting things while trying to solve the detection problem. Here are some of the techniques I tried.
Morphological operations
PDF417 barcodes have some useful characteristics. They tend to be high contrast, have nearly equal parts black and white, and contain lots of small, rectangular features. We can apply morphological operations to exploit these characteristics.

The idea is to first perform a dilation operation to remove small features (such as text and noise), then an erosion operation to emphasize dark, squarish features (lots of these in barcodes). And conveniently, ImageMagick supports these operations! Here’s the command I used to generate the above image.
$ magick barcode-photograph.jpg \
\( -clone 0 -morphology Dilate Disk:1 \) \
\( -clone 1 -morphology Erode Square:10 \) \
+append barcode-morphologied.jpgI like this technique. It’s easy, elegant, and surprisingly effective. The problem is determining the size of the morphological kernels. For the above images, I chose 1 and 10 by trial and error, but in general, they will vary by image, and there isn’t much margin for error. I couldn’t find a way do this reliably.
Edge guard detection
Okay, new idea. PDF417 barcodes have distinctive start and end patterns. We can scan the image for these patterns and from them deduce the location of the barcode.

My implementation worked well on clean images, but it failed on blurry images, where the black-white-black-white-black pattern tends to fade into gray-gray-gray-gray-gray. Also, it’s difficult to determine whether a series of pixels is a match. Blurring tends to erode black regions, making bar positions and dimensions uncertain. Printed text is also a problem, resulting in a surprising number of false matches.
A better implementation than mine could probably deal handle these issues. In fact, ZXing uses this method. But since I wanted to beat ZXing’s performance, I needed a different technique.
Hough transforms
A Hough transform can detect lines in images, even when the lines are broken or uneven. Barcodes contain lots of lines, so this seemed like a natural fit. In practice, though, these lines are very short and difficult to distinguish from background noise.
Barcodes also contain a lot of small rectangles. Although it’s often used to detect lines, the Hough transform can also be generalized to arbitrary shapes. The problem, though, is that rectangles have five degrees of freedom (compared to two for lines). The corresponding five-dimensional Hough space is infeasibly large to calculate and search.
All in all, the Hough transform is interesting, but it isn’t really helpful here.
Rectangle detection
When you think about it, the most significant features of a PDF417 barcode are those two large vertical black bars on either side of the barcode. They’re very resistant to blurring, rotations, and noise. Also, since they come in pairs about the same size and orientation, false positives can be easily filtered. So how do you detect rectangles in an image?

First, some preprocessing is in order. A small blur will fix high-frequency noise, such as grain. Low-frequency noise, such as from bad lighting or shadows, can be reduced by applying a strong blur and then dividing the original image by the blurred one. Then apply a small dilation to remove small features. Finally, you can safely apply a black-white intensity threshold.
You don’t have to perform this much preprocessing. But it makes the following steps faster and more robust.
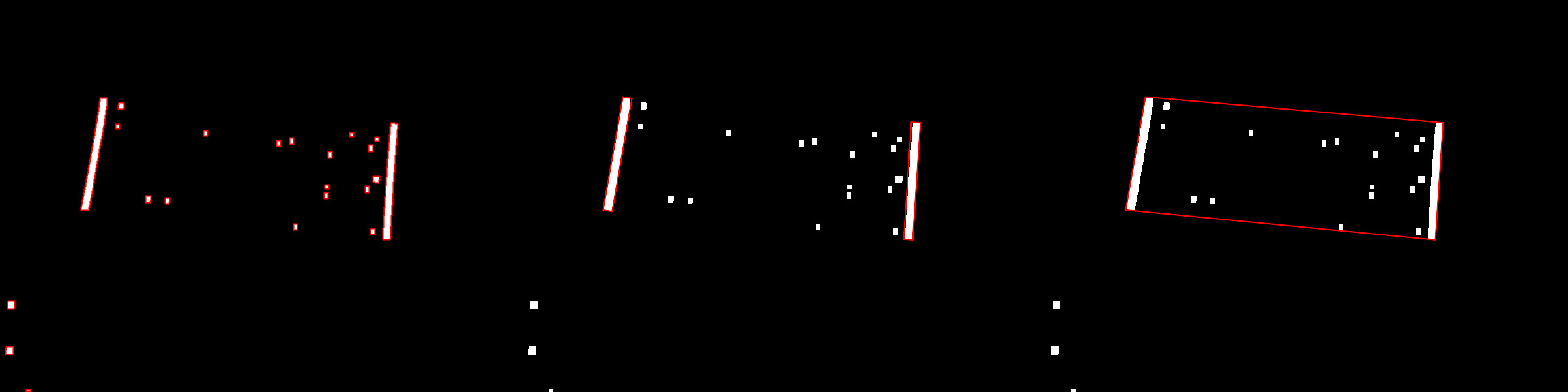
Next, find the connected components of the preprocessed image. You’ll also need to compute the area and outer boundary of each component. For performance, we’ll only do this for components of some minimum area.
Then, we’ll want to calculate the smallest rectangle containing each component. This would be easy if the rectangles had to be aligned to the coordinate axis, but we actually want the minimum rectangle of any orientation. Luckily, Arnon and Gieselmann (1983) have already invented a fast algorithm to do this. The main idea, proved by Freeman and Shapira (1975), is that one side of the minimum-area rectangle coincides with the component’s convex hull. Thus, we can compute the convex hull of each component and use that to determine the smallest bounding rectangle.
At this point, we have some components and their minimum bounding rectangles. To determine whether a component is a rectangle, we can divide the component’s area by the bounding rectangle’s area. If the component is a rectangle, the quotient should be nearly one. On the other hand, if the component is not very rectangle-ish, the quotient will be significantly less than one. For a while, I was pretty proud of myself for coming up with this, but it turns out this is a classic way to calculate rectangularity. Oh well.
Thoughts
Detecting PDF417 barcodes by rectangles is robust and reasonably fast. That said, a tremendous amount of research has been put into barcode detection (most of which I couldn’t access while working on Ruby417). So I strongly suspect there are faster and less complicated ways to do it. At the very least, you can take advantage of particular applications. In industrial situations, for example, you probably could control image lighting and quality. In a handheld scanner, the user would continuously adjust the scanner until detection.
There are also a few techniques that I never implemented. In particular, I still think that some sort of convolutional neural network should be able to perform at least as well as morphologies, and maybe without the limitations. I also think that a clever edge guard scanner should work nearly as well as rectangle detection while being simpler and using less memory.
Anyway, the image processing is a large and interesting field. I learned a lot from Ruby417, even though it’s pretty dead now. If you’d like to give it a try, though, check out the repository.